Local LLM Coding
There currently seems to be a price restructuring of LLM coding tools. While there is an arms race between the likes of Google, OpenAI, & Anthropic to create more powerful models there is an equal race to make money from them. If these companies are going to boil the ocean they would probably also like to make some money from it. capitalism
To make it worth it to them their pricing models are being rapidly iterated with the general vibe of “things are getting more expensive”…
So the first question this raised in me was: well how expensive would it be. But the second question was: Are local models good enough to replace or be used along side these large SOTA models.
Models like Gemma 4 & Qwen 3.6 show extreme potential for being local models offering great coding performance. Will they ever beat the magic Claude Mythos? Probably not or at least not a version that will run on my 64 GB macbook pro. I’m not building a $10,000 home AI server rack just to have it remind me how to use multi threading in python. That ROI does work.
Running local models is hard
There is for more involved than purely selecting your model. “Picking a model” is actually a complex question of trade offs that will vary greatly based on your machine and what tasks you want to use your model for. Hugging face lists 22 different versions of the Unsloth Qwen3.6 27B model.
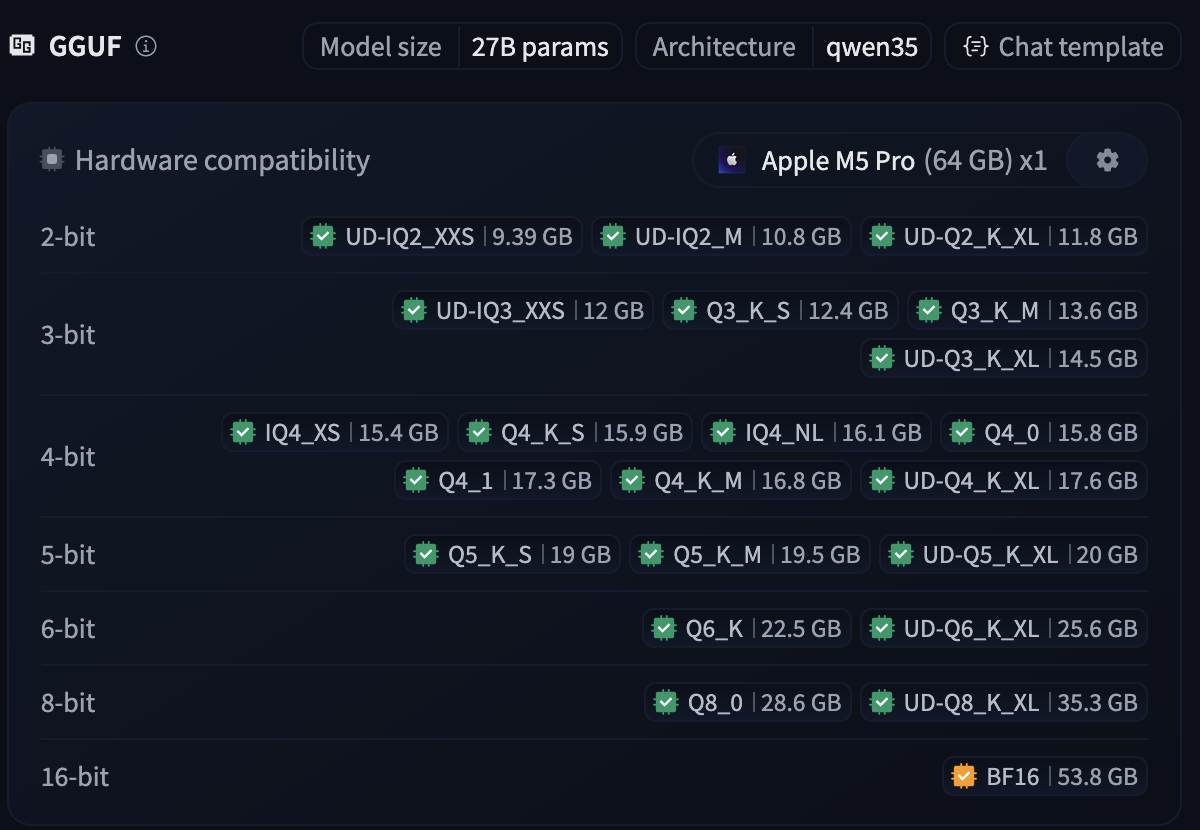
Different quant sizes will change the accuracy, speed, & size of your model. What is the difference in the real world between the Q4_1 at 17.3 GB and the UD-Q4_K_XL at 17.6 GB… I don’t know and finding out the difference is not straight forward.
Based on Unsloth’s reported benchmarks there differrent quant sizes differ but I will most likely have to do some very close side by side to really feel a difference.
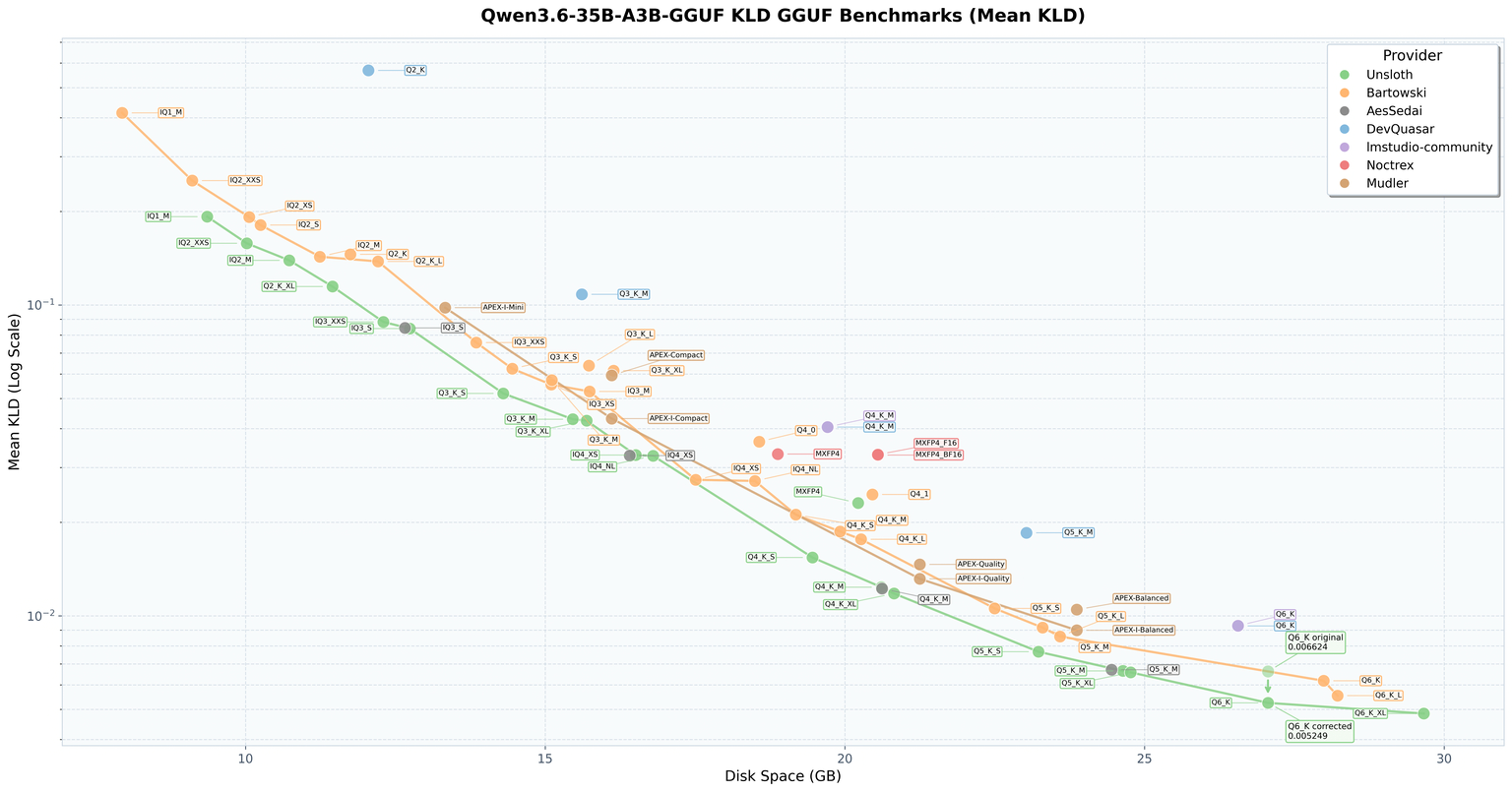
How do I actually run a model?
The main way I’ve seen so far is using llama.cpp. There are other tools such as ollama, LM studio, & Unsloth studio. But these either use llama.cpp under the hood or trade some amount of performance for a better UI experience. Given I’m already trying to run a paired down local model I want to get all the performance I can.